.png?width=259&name=WSAI%20Amsterdam%20Orange%20no%20dates%202000x300%20(1).png)

Since the release of the full-stack, full-scenario AI strategy at the end of 2018, Huawei has made a strong breakthrough in AI with its powerful computing advantages. In particular, Huawei released the world's most powerful AI processor Ascend 910 on August 23 this year, which earned a ticket for Huawei to enter the field full of world's top players. Giants in the industry quickly realize that Huawei has more than 5G and mobile phones. Huawei is investing greatly in basic research, which is helping Huawei seize the high ground in the future.
When we look back, however, the recent years of development has not ushered in an AI era with an established ecosystem, which brings more worries about the AI road ahead. Such worries were even stoked by the lack of computing power. In the seem-to-come AI winter, Huawei did not slow down its pace. Within one year, AI processors and computing frameworks were implemented successively. One could not help but wonder how Huawei gain insights, why they are confident, and how do they develop their technical knockout. We may find answers in Huawei Connect 2019 where the latest AI and cloud products and solutions are released to "make computing power more inclusive and algorithms simpler".
An AI Winter Is Coming?
In 1956, John McCarthy, an assistant professor at Dartmouth College, organized a workshop where the definition of artificial intelligence was formally proposed for the first time.In the next 60 years, AI has experienced two periods of slow development, the so-called "winters", but its development has never stopped.
At a conference in 2018, Kai-Fu Lee, CEO of Innovation Works, said in his speech that the biggest breakthrough in machine learning was made nine years ago and no major breakthrough was made afterwards.
Similar voices can be heard more and more often recently. Over the years, deep learning has been at the forefront of the AI revolution. Many believe that deep learning will lead us into a new era. However, the tide seems to keep receding.Questions and uncertainty are emerging about the road of AI ahead.
New Battlefield for Deep Learning
To put it simply, AI is implemented after reams of data are processed with the deep learning to form a model and this model is applied to a specific service scenario.In this regard, deep learning is an important driving force for AI.
Of course, deep learning is just one of the implementation methods of AI, and is a subset of machine learning. Deep learning itself is not independent from other learning methods as supervised and unsupervised learning are used to train the deep neural networks. But it has been developing rapidly in recent years, and some dedicated learning methods (such as residual neural network) have been proposed one after another, more and more people now regard deep learning as an independent method.
Deep learning was originally a learning process that uses deep neural networks to represent features. In order to improve the training effect of the deep neural networks, the neuron connection methods and activation functions have been adjusted. Many other ideas had been put forward in the early years. However, due to insufficient training data and computing power, those ideas failed to be incubated.
With the increasing volume of annotated data and continuous algorithm improvement, deep learning can now be used to perform various tasks, making it possible to implement machine-assisted scenarios, for example, automated driving. The rapid evolution of deep learning is attributed to the improvement of data, algorithms, and computing power. The data that can be used for training, especially the data manually annotated, is abundantly available. People can learn more from the data. Technological developments have made it possible to train ultra-large models, such as deep neural networks of thousands of layers, a size one could only imagine in the past.
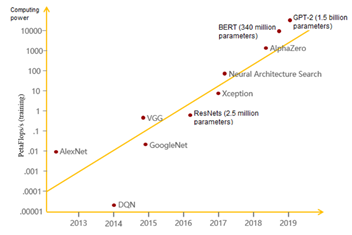
The complexity of ultra-large scale models increases exponentially. For example, BERT, a popular network in the NLP field, includes a maximum of 340 million parameters. Compared with a simple network such as AlexNet, ultra-large models require a computing power 10000 times greater. This is one of the important reasons why Open AI and other organizations say that AI computing power increases by about 10 times every year.
Due to the model complexity and the supply shortage by some component enterprises, the computing resources have been insufficient for research institutes, colleges, and universities. People often queue up to submit training assignments, and wait for a few days before they can get the results. This raises two fundamental questions: which research direction of deep learning does not have high requirements on computing power, and how to reduce algorithm requirements on computing power.
Huawei's AI Breakthrough
As surveyed, 20 ZB of new data is generated every year, and AI computing power requirements increase by 10 times every year. Such speed is much faster than the performance doubling time specified by Moore's Law. The industry has explore several ways to tackle this problem:
- Reduce the model size by means of pruning, weight sharing, and algorithm optimization to reduce the requirement for computing power, especially for mobile devices.
- Learn from small-size samples, which can also reduce the workload of data annotation.
- Design the acceleration hardware dedicated for deep learning to balance the chip area and efficiency of the CPU and GPU.
The fundamental solution is to improve the computing power supply through hardware and system design. For example, Huawei optimizes its deep learning capabilities by releasing the Ascend AI processors with the AI kernel and Da Vinci architecture, including the matrix computing unit (Cube Unit), vector computing unit (Vector Unit), and scalar computing unit (Scalar Unit), which combine the advantages of the GPU, TPU, and CPU. In particular, the efficiency of matrix multiply-accumulate operations commonly seen in the deep learning is improved severalfold. The Ascend 910 is designed for model training. A single chip can provide a computing power as powerful as 256 TeraFLOPS, twice the industry equivalent.
However, chips alone are not enough. They need to cooperate with high-speed, low-latency networks to release their full capacity. System-level optimization on data and model processing together can make possible a compute pinnacle beyond the current level.
Huawei has launched their new AI products in this field at Huawei Connect 2019. Let's see how they play their ace to provide a stronger computing power.
Meet Huawei and the entire AI community at this year's World Summit AI in Amsterdam. View the full programme, speaker line up and book tickets by visiting worldummit.ai
World Summit AI 2019
October 9th-10th
Amsterdam, Netherlands
worldsummit.ai