.png?width=259&name=WSAI%20Amsterdam%20Orange%20no%20dates%202000x300%20(1).png)

Artificial intelligence and machine learning are currently all the rage. Every organization is trying to jump on this bandwagon and cash in on their data reserves. At ThoughtWorks, we’d agree that this tech has huge potential — but as with all things, realizing value depends on understanding how best to use it.
We’re often approached by clients who want to jumpstart their AI initiatives by building a data lake. Often, this plan is seen purely as an infrastructure effort — without clearly defined use cases. The assumption is “if we build a robust data infrastructure, use-cases will present themselves later.”
In this post, we argue that software is best developed in thin, vertical slices that emphasize use cases and user outcomes, and data-intensive projects are no exception. When it comes to use cases that rely on rich, multi-format data, it can be tempting to start by creating a horizontal data platform layer, sometimes called a data lake. We are going to explore examples of how product thinking can apply to a project where a data lake is being considered as a solution.
What are data lakes anyway?
When we hear the term data lake, it usually implies:
- A centralized repository of data (operational, customer related, event streams, etc.) with proper documentation and fine-grained access control.
- Something built and maintained by data engineers so that data scientists can consume data and focus on developing ML use cases etc.
The term itself is often used in a very broad sense. Sometimes there’s a distinction between data lakes which are meant to hold only raw data and lake shore marts which hold processed bounded context (business function) specific representations used for further analysis. Sometimes data lake is used as a catch-all term to describe both (and maybe other things too).
This imprecise definition often leads to an unplanned expansion in scope, budget overruns, and over-engineering. It may be that an Amazon S3 bucket with proper access permission setup could be all you need as your data lake infrastructure for storing raw data. It’s important to define and establish a shared understanding of what data lake means for your organization at the outset.
Most big organizations would benefit from limiting the scope of the data lakes to store only raw data, and from setting up cross-functional product teams to develop ML applications using their own representations (lake shore marts) specific to their use case. Quoting from Martin’s post:
"A single unified data model is impractical for anything but the smallest organizations. To model even a slightly complex domain you need multiple bounded contexts, each with its own data model."
We’ll see an example of how such a setup could look a bit later in this post.
Build it; they will come
Data lakes seem particularly prone to “build it; they will come” mentalities. There could be multiple possible reasons for this.
Often, data scientists and data engineers are part of different teams. Data scientists are commonly aligned more closely to the business and data engineers closer to infrastructure and IT. This can give rise to siloed thinking and the tendency to consider a data lake purely as an infrastructure problem. Conway’s Law strikes again.
Next, pinning down the specific use-cases and value stream that the data lake will address is a hard problem. It involves talking to users and aligning multiple parties on a common goal. It’s tempting to substitute this hard problem with a material one which is purely technical.
Lastly, the common argument we hear for the “build it they will come” approach is that data lakes should support a wide array of use-cases and shouldn’t be constrained by a particular one. We agree with the premise that a data lake should support more than one use case. We’re just arguing against too much up-front architecture and design that happens before use cases are considered.
Pitfalls
Designing a data lake in a top-down fashion, without an eye on the end use cases, will almost inevitably result in a poor problem/solution fit.
Without actually using the data to develop models and seeing them work in the real world, without learning and iterating on the feedback, it’s very hard to tell what the optimal representation of your solution is.
In reality about 70–80% of the effort in building an ML application is cleaning and representing the data in a format specific to the use case. It makes little sense to put a lot of effort in data preprocessing without knowing how it will be used to build ML models. The people building the model are likely going to have to reinvest the effort to do similar work.
Let’s illustrate this with a hypothetical example:
An insurance firm has plans to build a data lake which will revolutionize how its data scientists or BI analysts access and analyze data and generate insights for the company. The firm has grown over the years through merger and acquisition of many smaller insurance companies —hence, it doesn’t have a single, consolidated view of their customer. Instead, its customer details are fragmented among maybe 20 different subsystems based on the product line (health insurance, vehicle insurance, pet insurance, etc.).
Now as part of its data lake initiative it wants to create a consolidated view of the customer. The company spends months coming up with a single definition of the customer which works for all possible future use-cases and are only medium-happy with the result at the end. You can see why this is a hard thing to do.
- There probably is no single definition of the customer which works for all the future use-cases equally well.
- Fetching customer information, matching and deduplicating them from 20 disparate system is a non-trivial task. This involves massive coordination among different product teams.
Not knowing how this consolidated view of the customer will be used will make this task even harder and open-ended. It’s not possible for the company to prioritize its work and make informed decisions when trade-offs are involved.
Some data lake initiatives are even vaguer and complex than the above example. They aim to consolidate all business entities and events into a central data infrastructure.
If users don’t take care early in the process to ensure that the data contained in the data lake is used, there’s a real risk that the data lake becomes a data swamp — basically a dumping ground for data of varying quality. These cost a lot to maintain and deliver little value to the organization.
Product thinking for data lakes
We propose a more bottom-up approach to realizing the data lake — one that builds one vertical slice at a time. Let’s see how this could look with the above insurance company:
It starts with the following initial set of use cases:
- Identifying fraudulent claims so that they can select claims for deeper manual investigation; they have a business goal of reducing fraud by 5% this year.
- Predicting weather patterns so that they can advise customers to protect their vehicles by bringing them inside when there’s a high chance of storms — thereby reducing vehicle damage claims by 2%.
- Upselling other insurance products to the customer based on the products they already have. The goal is to increase the conversion rate for online upselling by 3%.
The insurance company sets about the project as follows.
Before the start
There’s a high-level architecture in place and a governance structure that covers documentation standards, guidelines for the required specificity of data, backward compatibility, versioning, discoverability, etc.
A few upfront technical decisions are made at this point, for instance, the decision to go on-premise or in-cloud, which cloud provider to use and which data store to use. These are decisions that are harder to reverse later in the project, hence must be few in number.
There’s an architectural team in place which ensures the fidelity of the architecture and observance of the governance structures while the platform evolves and applications are built on top of it.
There’s a cross-functional delivery team containing both product owners from the business, data engineers and data scientists to productionize the use-cases.
Working through use-cases
The project team knows it has to start small, so it picks the fraud detection use-case as the first vertical slice. The team knows that health and vehicle insurance contribute towards the majority of the claims, so it decides to focus on just these verticals initially. Raw customer and claims data from these two verticals is pulled into the data lake. It’s cleaned and aggregated and represented in a data mart specific to this use case. The next step is to build fraud detection models using these and productionize them.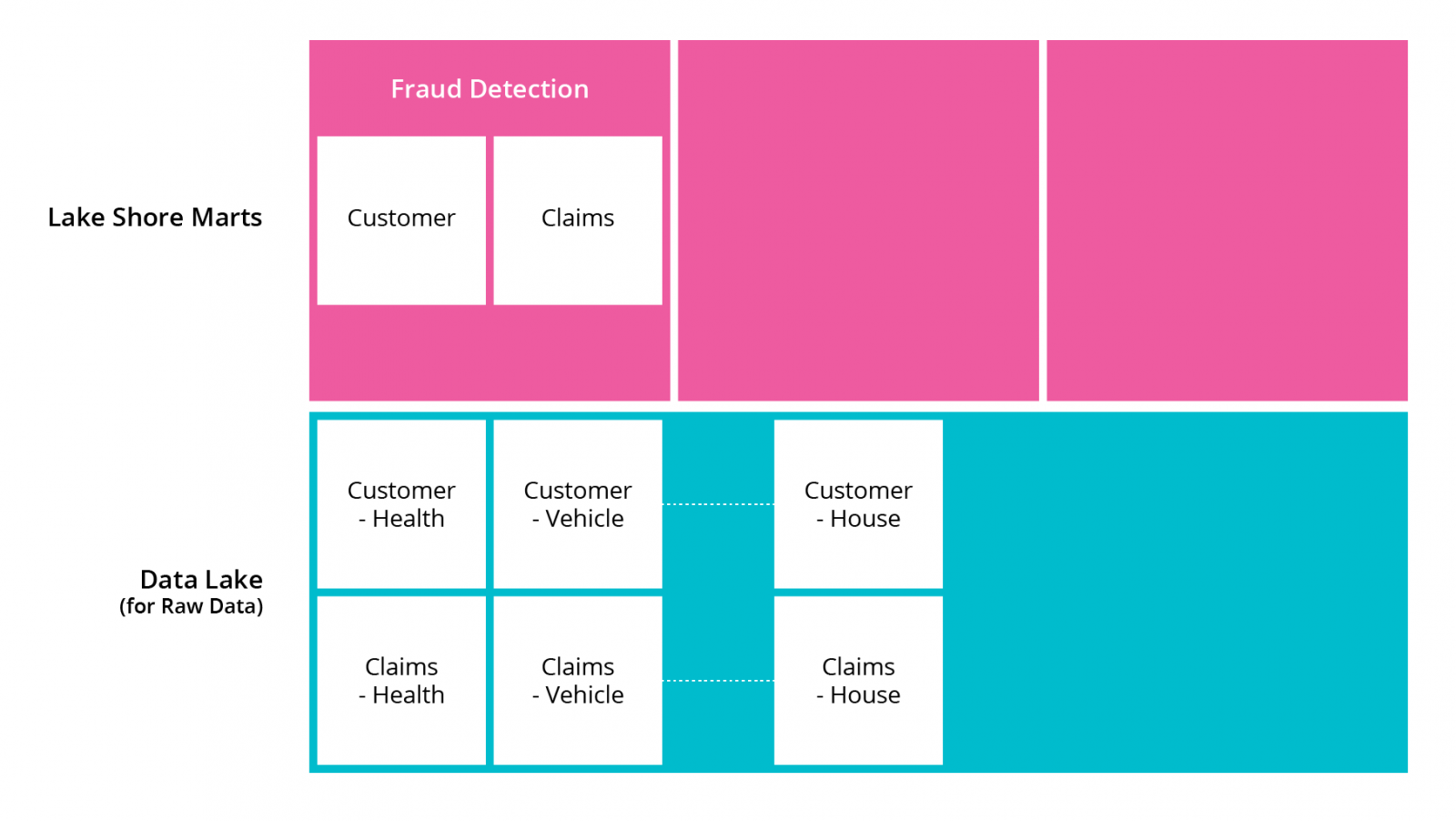
Now that the first version of a fraud detection model is in production, the team observes that it could improve the model with additional fields which aren’t currently collected. The data scientists who uncovered this are working closely with the data engineers so that this feedback can be acted on quickly. Together they swiftly figure out how to collect these new fields and adapt the model. The new model is significantly better than the first.
This approach would entail using two out of 20 data sources saving themselves a lot of potentially wasted effort — and delivering more effectively towards the 5% target. 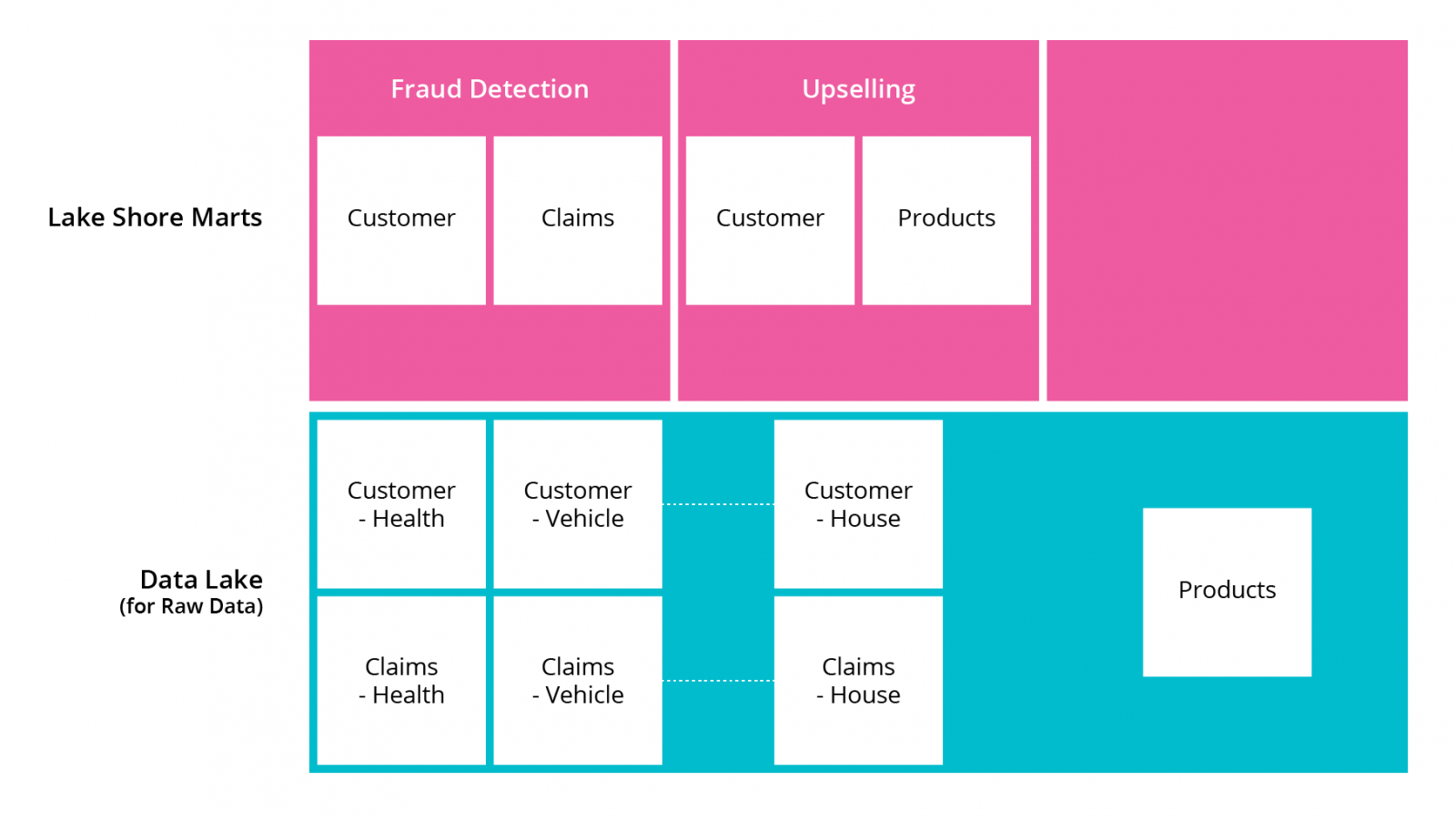
Now the fraud detection model is up and running and generating value for the company; the company can focus on leveraging customer data for the upselling use-case. For this, it adds product data and house insurance related customer data to the lake and uses existing customer data to have new representation in their own bounded context. Again, this provides a more effective way to create models that will deliver towards the target of a 2% increase in upselling.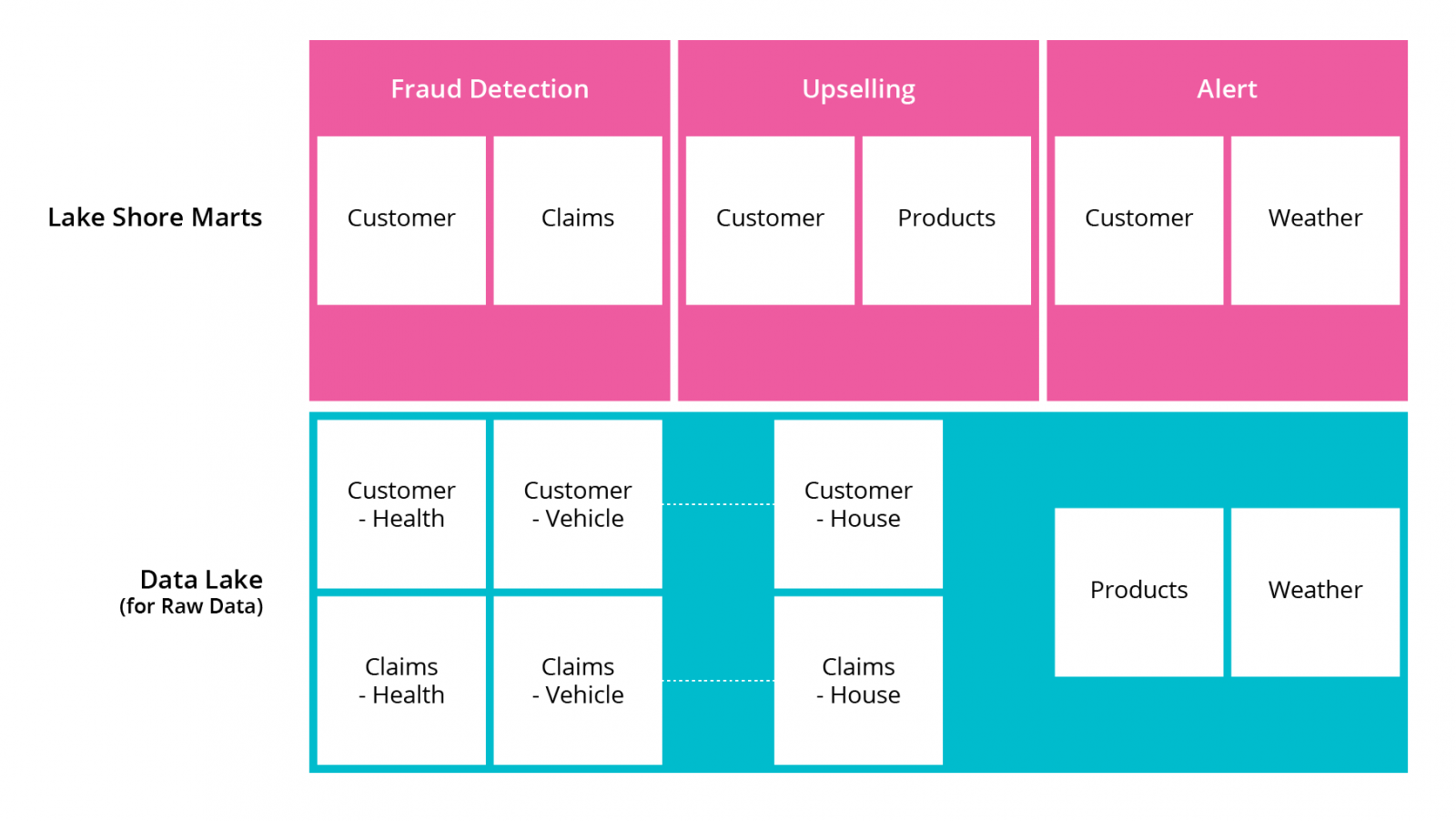
Now the company can move on to the alerts use-case. This is a more complex model and involves leveraging all the raw data they have used so far and adding an additional source: real-time weather data.
They have to rework some of the raw customer data so that it’s appropriate for the new use-case. The benefit of doing this as rework rather than upfront work is that they now understand more about the requirements for the first two use cases. This allows them to do just enough work to create value and not waste effort on speculative work which may be wasted.
To be clear: this process can be parallelized to some extent. We’re arguing for working on articulated use cases — not that all work on other use cases must stop until a use case is complete.
In summary:
- There’s no single, one-size-fits-all definition of a data lake. To guarantee you get what you want, be specific about the problem you’re trying to solve.
- Work on articulated use-cases and measurable business goals. Test them and get feedback. Treating data projects as products and not merely as infrastructure will save a lot of wasted effort.
- Allow your data scientists to work as closely with your data engineers as possible. Chances are you will achieve results faster, the results will be more closely aligned with the purpose they’re trying to solve, and the joint ownership will mean the maintenance effort will be easier to coordinate.
Join ThoughtWorks and the global AI community at World Summit AI 2019 this October!
World Summit AI 2019
October 9th-10th
Amsterdam, Netherlands
worldsummit.ai