.png?width=259&name=WSAI%20Amsterdam%20Orange%20no%20dates%202000x300%20(1).png)
We show ground-breaking components of machine learning so artificial intelligence is less abstract.
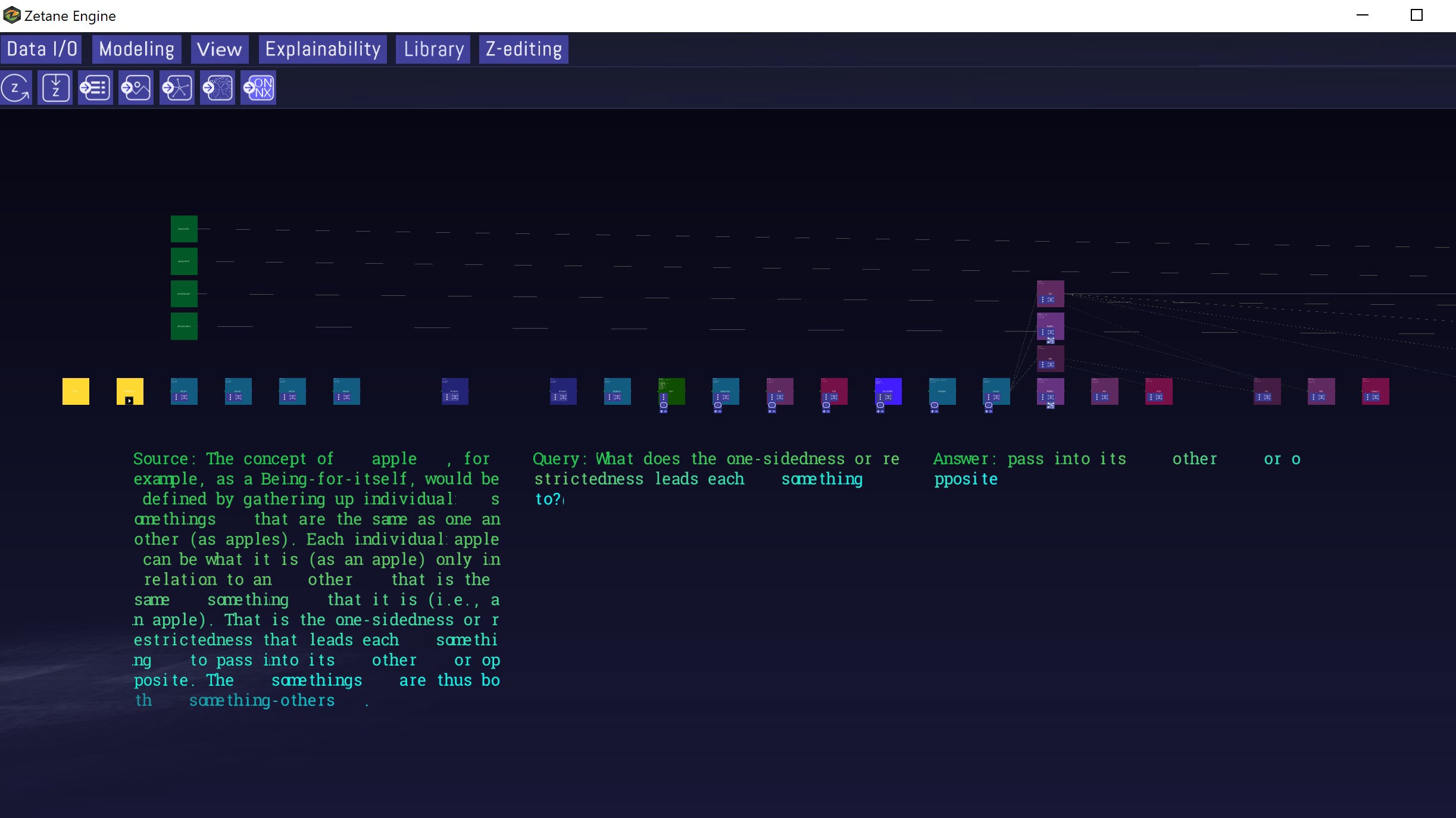
Zetane provides a new environment to work with complex neural networks and datasets, transforming abstract AI projects into tangible concepts. Here is a screenshot of working with the neural network of the BiDAF model that is processing the Stanford Question & Answering Dataset (SQuAD).
Weat Zetane are all about democratizing AI, but getting to the laudable goal of empowering more people within AI innovation requires many steps along the way. One beginner’s step on our journey involves peeling away the abstract nature of AI like the skins of an onion. We peel these layers of abstraction away by presenting fundamental components of machine learning in ways technical and non-technical professionals can appreciate. This will be a repeated theme of ours on the Zetane blog, which we call:
This is what AI looks like.
To start us off we present here the Bidirectional Attention Flow model, or BiDAF.
At first glance, this model looks to be a practical attempt to understand elements of unstructured text. Its development in 2016 marked a major step forward in Natural Language Processing (NLP) for Question and Answer tasks. That may at first sound straightforward. This basic task, however, has huge implications in business as a tool to automate important tasks like customer support inquiries or common requests for information. It thus comes as no surprise that this model attracts fervent investment and research. Aside from the model’s commercial applications, BiDAF marks an important milestone in opening the doors to a not-too-distant future of appreciable Machine Comprehension. Building on knowledge gained from BiDAF, the machine learning community has since brought forth the superior NLP models of BERT and ELMo.
For the time being, let’s take a closer look at BiDAF and some of its complexities, beginning with an image of the full neural network.
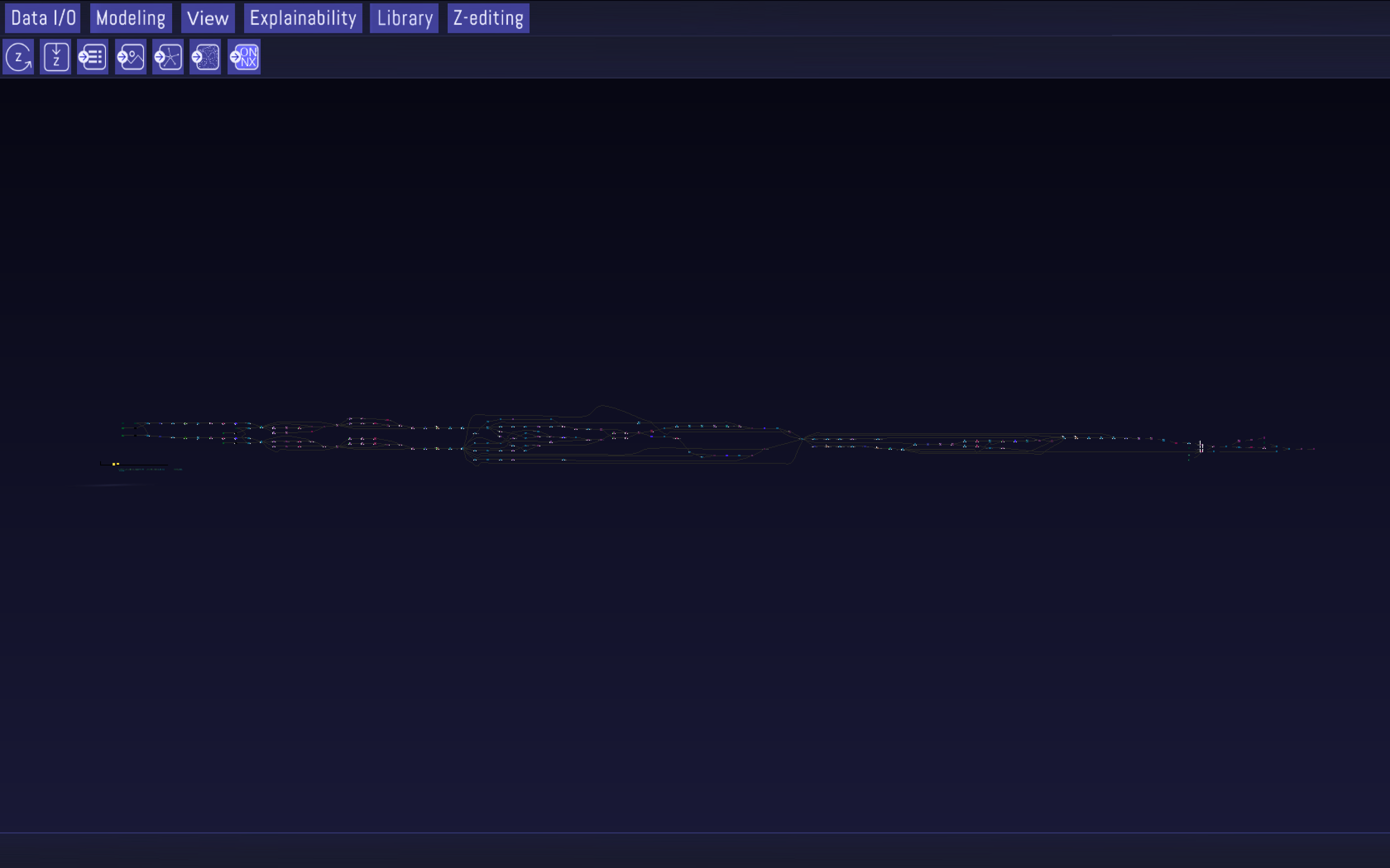
A display of the BiDAF model in Zetane zoomed out to show the extent of the full neural network. It is complex!
The dimensions of the BiDAF model should grab one’s attention. When viewing the model end-to-end, it is difficult to make out the appreciable complexity of the neural network. Let’s zoom in for a closer look, focusing on the left-side input layers of the network.
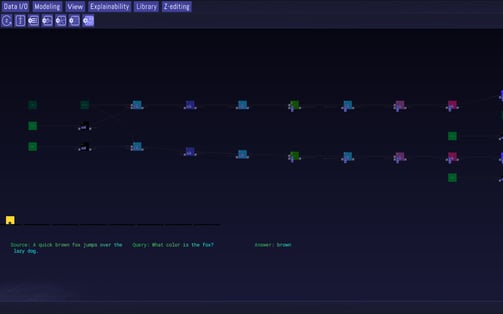
Display of a source text, query and answer made possible by the BiDAF model trained with SQuAD. The mid-green squares on the far left and far right represent four distinct input layers.
The above image shows a typical ‘source’, being text with a jumble of information. Upon querying the basic question ‘What color is the fox?’, the model predicts the best answer is ‘brown’, being spot-on. Of particular interest here are the four input layers of the neural network, represented by the mid-green squares. Machine-learning models often have one input, but the specifics of the question-and-answer task requires a bit more work in terms of structuring and analysing the data as text. Let’s inspect further to better understand why that is the case.
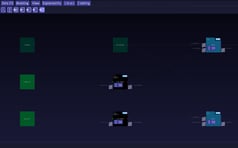

Left: the first two input layers of BiDAF. Right: the latter two input layers of BiDAF
The first input layers are the context_char and query_char, being abbreviations for the inputs of character-level representations of the text and the question (“query”). The latter two inputs of contex_word and query_word are where word-level representations of the text and question become incorporated in the analysis by the neural network. This architecture shows there is an initial processing of the text and then a subsequent assessment of the words in order to achieve an appreciable level of language comprehension. Overall, the BiDAF model aims to identify a context and then keywords integral to the context, where the layered design of the neural network makes it easier for the model to tease out the answer keyword from the general context. It’s interesting to note that the model does this by converting all text into math, namely vectors, meaning its ability to understand text has little to do with text per se and is in fact a probability-based prediction of pairing words.
To conclude our overview of BiDAF we present a short video capture of the model in our environment for machine learning projects. Here is a display of the breakdown and analysis of the vectorized text information as it passes through nodes of the neural network. We intermittently show the internal metrics of the information at the nodes, called tensors. The take-home message here is that whether data is in the form of text, images, video or whatnot, a neural network transforms that information into a universal language of advanced — and arguably aesthetic — statistics.
This is what AI looks like.
YOUR GLOBAL AI EVENTS CALENDAR
Here is your Global AI Events Calendar where you can meet your fellow 54,000 InspiredMinds community members of business leaders, heads of government, policy makers, startups, investors, academics and media.
WORLD SUMMIT AI WEBINARS
INTELLIGENT HEALTH
9-10 September 2020
Online
INTELLIGENT HEALTH AI WEBINARS
INSPIRED AI SERIES
Sept – Nov 2020
Online
inspired-minds.co.uk/inspired-ai
WORLD SUMMIT AI @ INSPIRED AI
14 October 2020
Online
WORLD AI WEEK
12-16 October 2020
Amsterdam, Netherlands
INTELLIGENT HEALTH UK
3-4 March 2021
London, UK
WORLD SUMMIT AI AMERICAS
20-21 April 2021
Montreal, Canada